Grâce aux Google maps notamment, on a vu apparaître sur le Web une floppée de mashups visant à permettre des interactions locales entre personnes, ancrées dans un territoire. De manière balbutiante, PlaceOPedia fait par exemple le lien entre des articles Wikipedia décrivant des lieux et la localisation de ces lieux sur une Google Map. On est encore bien loin d’avoir des outils qui permettent de créer du lien social sur un territoire donné pour lutter contre les phénomènes d’exclusion. D’abord parce que les territoires sont à peine représentés sur le Web, ensuite parce que les logiciels de réseautage social sont bien peu efficace pour réellement créer du lien, enfin parce que le mixage des deux tarde à donner une quelconque forme de résultat utile.
Archives de catégorie : My wishlist
Connecting romanian gypsies
Jean-Pierre is member of a French NGO dedicated to extreme poverty in France. He works closely with some nomad gypsy families who live in poverty near Paris. He sometimes brings them his laptop, a digital camera, a printer and an Internet connection and made some experiments with Skype and other software. They enjoy getting some news about Romania through online newspapers and websites. The young father of one of these families told Jean-Pierre how cool it would be if computing allowed him to get some recent pictures from his 5 years-old son who stayed in Romania. It has been 2 years since he last saw him. Another person is trying to get in touch with their mother who suffers from some disease in Romania.
When I read that on Jean-Pierre’s blog, I started trying to identify some Romanian volunteer who would visit that remote family with a digital camera, take some pictures and send them back to Jean-Pierre’s laptop via the Internet. I wrote a blog entry for this. I asked a Romanian colleague in the company I was working for at the time. I also sent a couple of emails to some Romanian IT services companies which offer offshore consulting services to French customers. Unsuccessfully.
Some time ago, a French guy in Bucharest contacted me in order to volunteer. Unfortunately, he was not located near the Romanian area where these families are, as Jean-Pierre explained us. So he could not help.
I don’t know much things about these families in Romania. As far as I know, they are in the area called Mehedinti, near the city of Girla Mare. I assume they are gypsies. Another Romanian colleague told me a bit more about this area. It is a very poor rural area with small mountains (up to 1000m high) near the Romanian border with Bulgaria, Serbia and Montenegro. He told me that the Romanian government had been saying for years that no such extremely poor and excluded gypsies exist in the country (until the European Union required from them that they recognize the importance of their minorities). From what I saw about gypsy families in the Czech Republic, I imagine that they live far from any town or village, without any sort of infrastructure. Maybe the road that leads to their place has no asphalt. Maybe they are in the middle of a forest, in some muddy place (Dilbert’s Elbonia anyone?). Maybe they live in a giant soviet-like sinister building in the forest where broken windows have never been replaced (this is the reason why they might be interested in linux BTW). They probably don’t have electricity nor any phone line. They most probably live on the fringe of society as their French cousins do in some way. I wonder how far such a picture is from reality. I hope I would be wrong.
Anyway, as I joined a new company, I investigated our presence in Romania still in search for some would-be volunteer. Our corporate directory randomly gave me the coordinates of one of our employees in Bucharest. I sent him an email like I would be sending a bottle into the sea. How surprised I am by his answer!
He tells me that he asked all of his colleagues about what we can do. One of them knows someone in this rural area. This local person is the head of a mountaineering club. He tells us that he is very enthusiastic about helping there. At the same time, my employer might be motivated by the idea of connecting some unconnected families in such a rural area and may support such an initiative. Or I am once again too naive. Anyway I am now investigating this opportunity internally. I also have to answer this mountaineer and try to understand a little bit more his motivations and expectations. I have to get sure that he does not think this would bring him any money because this is so far from what I am interested in.
Mise en relation par le web sémantique
Le projet européen de recherche Vikef vise à développer des technologies de mise en relation de personnes grâce aux technologies du Web Sémantique. Principale application envisagée: la mise en relation de professionnels dans des salons et de scientifiques lors de conférences. Lancé en avril 2004, le projet prendra fin en mars 2007. Ce projet est mené notamment par Xerox, l’insitut Fraunhofer et Telefonica.
Spontanément, je ne peux m’empêcher de me réjouir d’un tel projet et de m’inquiéter de l’utilisabilité des applications qui vont en découler: va-t-on demander aux utilisateurs de modéliser leurs centres d’intérêts? Ca ne me paraît pas très réaliste. Je demande à voir !
A la recherche des Innovations Internet d’Utilité Publique
Cet été, j’ai exploré avec plusieurs d’entre vous la jungle de l’innovation, de l’Internet et des projets d’utilité publique. A l’intersection de ces trois domaines, mon expédition visait à identifier des innovations Internet répondant à des enjeux d’utilité publique.
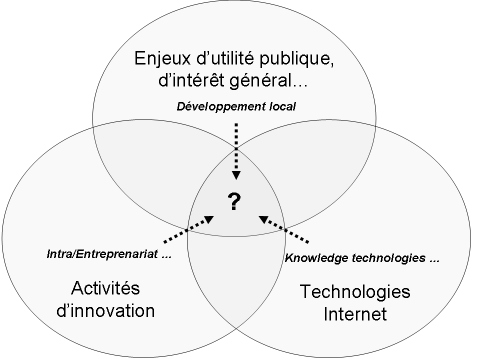
Avant de vous raconter cette expérience et de vous inviter à la poursuivre via ce blog, laissez-moi vous dresser le tableau avec quelques définitions préalables :
- Innovation : cf. qu’est-ce que l’innovation ? pour ma compréhension du sujet ; l’innovation relève pour moi d’une démarche de recherche entreprenariale.
- Internet : pas de doute, on sait ce que c’est ; mais pour être plus précis, mon intérêt est centré sur les technologies de gestion/traitement des connaissances issues de l’Internet (web sémantique, data mining, personnalisation, technologies pour le knowledge management) et les technologies Internet de mise en relation (social software), bref partout où il y a du lien, de la complexité et des réseaux relationnels (entre concepts, personnes, objets)
- Enjeux d’utilité publique, intérêt général : le champ est large et couvre aussi bien le monde associatif, le secteur public et l’économie sociale que des services Internet dont on aurait aujourd’hui du mal à se passer (Google est-il devenu un service d’utilité publique ?) ; mon intérêt est plus particulièrement centré sur le développement local.
Cet été, j’ai donc profité de quelques semaines de mes vacances pour explorer cette terra incognita, avec certaines questions en tête. Peut-on profiter des techniques issues de l’Internet pour changer de manière durable (innover) la société (utilité publique) ? Qui en parle et qui en fait ? Que faire (en tant que bénévole ou professionnel) pour contribuer à de telles innovations ? De rencontre en recontre, les questions se sont accumulées : les “innovations Internet d’utilité publique” (IIUP pour les intimes), est-ce que ça existe vraiment ? IIUP = OVNI ? qu’est-ce que c’est précisément ? On trouve assez facilement des exemples d’IIUP relevant de bricolages bénévoles de haute qualité mais cantonnés au monde du bénévolat et de l’amateurisme à petite échelle ; peut-on faire de l’innovation Internet d’utilité publique à grande échelle et avec des moyens vraiment conséquents ?
Voici donc le récit de nos rencontres (je change vos prénoms par anonymat de politesse…).
Chez un gros éditeur logiciel américain, Benoît, directeur commercial a la gentillesse de me recevoir. C’est l’un de mes anciens fournisseurs, avec qui je garde un bon contact. Bon, franchement, les IIUPs, ça le laisse un peu sec. Mais pour lui, pas de doute, il faut regarder du côté de l’Agence pour le Développement de l’Administration Electronique afin de repérer des projets innovants de grande ampleur. La Feuille d’impôt via Internet change-t-elle la société ? Mmm… Benoît m’avoue que, franchement, lui ne se voit que comme un vendeur de plomberie. A la limite, ce pourrait être ses clients qui pourraient faire des choses innovantes avec les logiciels qu’il leur vend. Il pense que l’un de ses collègues pourra peut-être me donner des pistes plus précises car il vend pas mal auprès du secteur public.
La jungle semble bien inextricable dans la région du commerce informatique professionnel : de la techno, certes mais peu ou pas d’innovation et, comme on peut s’y attendre, une absence totale d’utilité publique. Je dois mieux cibler mon approche.
Jean-Louis, vieux loup de l’associatif et du développement local et directeur d’un cabinet de conseil en conduite du changement, me reçoit avec sa générosité habituelle et m’invite dans sa brasserie préférée. Miam. Ma démarche le déconcerte peut-être un peu mais qu’à cela ne tienne, il m’accorde une attention toute perspicace. Il me parle des tentatives d’une grosse ONG française pour approcher les grandes entreprises sur des projets de type IIUP. Il me parle aussi du projet Digital Bridge d’Alcatel. Mais il me met également en garde contre l’auto-enfermement qui me guette si je me concentre sur la techno et les théories plutôt que sur la richesse de mon prochain, contre le mirage de la toute-puissante technologie qui cache l’homme et contre la méfiance voire le dégoût que la plupart des vieux loups du monde associatif conservent vis-à-vis de l’économique et du monde de l’entreprise. Pour me préserver de perdre contact avec mon prochain, il me prescrit la lecture de Simone Weil. Pour poursuivre mon exploration et découvrir des IIUPs, il me recommande de suivre la piste de la (petite) équipe Digital Bridge d’Alcatel.
Je ne suis pas encore passé à la pharmacie bibliothèque mais j’ai déjà compris que je tenais avec Alcatel une piste fragile mais prometteuse. Y a-t-il quelqu’un d’Alcatel dans la salle ? Poursuivons notre exploration.
Philippe est un entrepreneur aguerri dans le terrain du knowledge management. Innovation et KM ça le connaît. En plus, il a des projets plein la tête. Distribuer de la connaissance médicale “prête à l’emploi” à des médecins africains, ça fait longtemps qu’il y pense et qu’il s’y prépare ! Problème… Philippe est préoccupé par de gros soucis avec ses nouveaux associés.
Ce n’est pas le moment pour explorer avec lui plus avant la jungle des IIUPs. Il faut d’abord qu’il se rassure sur son gagne-pain. Ce n’est que partie remise.
J’avais rencontré Daniel dans un cadre associatif. Elu local en province, c’est par téléphone que nous nous entretenons. Il maîtrise parfaitement le sujet des projets coopératifs d’innovation locale grâce aux technologies Internet. Mais la dimension entreprenariale des innovations Internet d’Utilité Publique lui est étrangère. Pas de doute pour lui, l’intersection de l’utilité publique et de la technologie Internet grouille d’initiatives associatives locales, fourmille de projets d’espaces publics numériques, de sites Web citoyens, d’îles sans fils. Mais de là à parler de démarche économique ou de social entrepreneurship, c’est un pas que nous ne franchirons pas ensemble par téléphone. Pour lui, la bonne piste à suivre (si piste il y a), c’est sans doute celle de la FING. Ou peut-être à la limite de France Telecom, mais bon… avec peu d’espoir de succès.
Mmm… La FING, bien sûr, c’est facile. France Telecom, ça m’étonnerait, mais il faudra bien de toute manière explorer cette piste confuse, trompeuse et difficile. Mais par où la commencer.
A la FING, c’est naturellement vers Fabien que je me tourne. Fabien est une sorte de consultant comme on en recontre peu. Il connaît l’économie sociale comme sa poche. Il maîtrise l’Internet comme pas deux. Et les innovateurs, c’est son coeur de métier. Pour couronner le tout, c’est un copain à moi. Bref, l’interlocuteur idéal. Les Innovations Internet d’Utilité Publique, il en rêve. Il regrette les faibles moyens qui sont mobilisés sur ce sujet. Il n’est pas encore très au fait de la mode américaine du social entrepreneurship : mettre la force économique au service d’innovations d’intérêt général. Sans parler d’économie de communion. Mais il pense que c’est une piste qui a du sens. Peut-être ne découvrirais-je pas d’Eldorado des IIUPs mais ça ne l’étonnerait pas qu’un jour… quelqu’un comme vous, lui ou moi contribue à en construire. Il m’aide donc à cibler au mieux la poursuite de mon exploration, me suggère de vous raconter toutes mes découvertes sur mon blog et m’ouvre tout son carnet d’adresse (qui est sans fond, j’en témoigne).
Il m’introduit notamment auprès de son boss, Daniel et auprès de Claude (France Télécom). Il me semble qu’on avance ! Merci !
Daniel, consultant expérimenté en innovation publique et grand chef de la FING, se révèle également d’une grande sensibilité à l’intérêt de ma quête des IIUPs. Il y contribue à son tour en me recommandant auprès de responsables de l’innovation de plusieurs de nos vénérables institutions publiques françaises. Pour lui, les acteurs les mieux placés pour mener des IIUPs sont sans aucun doute les collectivités territoriales. L’Etat a-t-il encore vraiment les moyens de mener de telles innovations à grande ampleur ?
Il faut poursuivre dans ce sens. Chemin faisant, les contacts et les pistes se multiplient mais je sens que j’avance dans la bonne direction. Je sais déjà que je ne suis pas le seul à croire à la possibilité de changements sociétaux de belle ampleur et motorisés par des technologies issues de l’Internet. Les IIUPs ne sont pas des OVNIs (“je veux y croire” en tout cas). Allez, en avant…
C’est dans la jungle du RER que je tombe sur mon étape suivante : j’y reconnais Xavier. Je l’avais rencontré sur recommendation d’un très bon ami à une époque où je m’intéressais au rôle des ingénieurs dans le secteur public. Si je ne me trompe pas, il doit en connaître un rayon sur les innovations dans le secteur public. Pour peu qu’il s’intéresse à l’Internet… Je l’aborde et lui demande ce qu’il devient. Surprise : il dirige justement des recherches sur le knowledge management pour un grand ministère ! Double-surprise, un ministère s’intéresse au knowledge management à tel point qu’il finance des projets de recherche sur le sujet ! Xavier m’accorde donc un bon morceau d’après-midi pour que nous partageions nos passions communes et notre intérêt pour les innovations Internet d’utilité publique. J’y découvre comment les techniques de représentation des connaissances pourraient être utilisées pour formaliser l’expertise métier contenu traditionnellement dans les énomes annexes techniques des plus gros appels d’offres publics. J’imagine le champ des applications : aide au dépouillage des réponses à des appels d’offres complexes, contrôle semi-automatisé de la conformité des livrables des appels d’offres, formation des nouveaux ingénieurs du secteur public, etc. Comme pour de nombreux autres business, les métiers traditionnels de l’Etat peuvent avoir à gagner à mieux gérer leurs connaissances. J’y apprends également l’existence de projets d’universités en ligne ouvertes dont l’un des objectifs est de démocratiser l’accès à la connaissance par la mise en commun de contenus pédagogiques d’intérêt public. L’université de Phoenix, leader privé de l’enseignement en ligne, sera-t-elle un jour concurrencé par des services publics européens d’enseignement en ligne pour ingénieurs par exemple ? De tels projets se préparent mais n’en sont qu’à l’état larvaire semble-t-il. Et, encore une fois, ils semblent s’appuyer davantage sur du bénévolat et l'(in)attention bienveillante de l’Etat que sur une démarche volontaire d’innovation durable et économiquement viable. Comment aller plus loin ?
Il est temps de suivre les pistes repérées précédemment. Comment ça se passe du côté des collectivités locales ?
Alain dirige les projets “nouvelles technologies” d’un conseil général rural . Alain, l’un de mes anciens clients, a un profil rare : c’est un ancien entrepreneur reconverti au secteur public. L’économique, il sait ce que c’est. La techno, ça le fait vibrer. Et le secteur public, il y consacre sa vie professionnelle. Il me confirme immédiatement que ce sont les collectivités territoriales qui sont les plus susceptibles d’être innovantes en matière de nouvelles technologies (comparées à l’Etat). Ceci s’explique notamment parce qu’elles ont une pression (électorale) beaucoup plus immédiate et des enjeux plus concrets à traiter. Cependant, les budgets ne suivent pas forcément les augmentations de responsabilité (et d’effectifs). Pour Alain, les facteurs clefs de succès pour un conseil général qui veut mener à bien des projets numériques sont le fait de pouvoir s’appuyer sur des grosses communes, de savoir gérer des relations multi-partenaires et de savoir faire face à l’usager-client. Alain se prend à rêver avec moi aux départements qui lui semblent avoir les plus beaux challenges à relever (et les plus importants moyens ? ) en matière de nouvelles technos pour mener des innovations d’utilité publique : le 93 et le 59. En administration centrale, c’est peut-être le ministère des finances qui est l’administration la plus intéressante de son point de vue. Mais bon, personnellement, je ne me sens pas vibrer devant une feuille d’impôt fut-elle électronique. OK, c’est utile. Et c’est innovant. Un peu. Un tout petit peu, à mon avis. Mais je suis exigeant en la matière. Alain m’indique quelques références de consultants spécialisés sur son domaine. Mais j’ai déjà renoncé à trouver des consultants porteurs d’innovation. Le métier du conseil consiste trop souvent à limiter au maximum les risques (du consultant et, parfois du client) et à resservir le plus grand nombre de fois les mêmes recettes et ce, le plus cher possible. Le métier du conseil, c’est de comprendre le client, pas de prendre des risques à sa place. Confirmant les indications de Daniel de la FING, Alain me recommande de me raprocher de la Caisse des Dépôts : au croisement de l’économique et des collectivités locales, la CDC doit avoir une vue privilégiée des innovations Internet d’utilité publique auxquelles nous rêvons.
Sur ces bons conseils, je me taille donc un chemin jusqu’à la caisse des dépôts. J’y découvre une équipe dédiée à l’innovation au service des collectivités locales et des usagers des services publics. Ai-je enfin découvert l’eldorado des innovations Internet d’utilité publique ? Peut-être en partie. On y parle investissement raisonné dans de nouvelles offres de services publics économiquement rationnelles voire profitables à long terme. Comme souvent, les premiers sujets explorés ont été les infrastructures : espaces publics numériques pour l’accès du public à l’Internet dans des lieux publics, et depuis quelques années infrastructures réseaux et alternatives aux offres de l'”opérateur historique” (il faudra que je finisse par aller le voir, celui-là aussi…). Mais on parle aussi de service public en ligne personnalisé, de cartable numérique et autres grands projets d’utilité publique. Et les moyens mobilisés dans la Caisse des Dépôts semblent bien réels, au moins en terme de personnel. Bien sûr, la caisse n’a pas une culture d’innovation façon Silicon Valley ! Mais se pourrait-il qu’au sein d’une si vénérable et rhumatisante structure susbiste une petite équipe d’irréductibles innovateurs ? Se pourrait-il que tous ces projets d’innovation réussissent à éviter les écueils des clientélismes politiques et des échéances électorales tout en restant axés sur de véritables enjeux d’utilité publique ? Ce serait tellement bien si c’était vrai… Ce n’est pas ce premier entretien qui me permettra de me faire une idée définitive sur la question. En tout cas, j’ai encore une fois obtenu la confirmation qu’il existe des projets Internet d’utilité publique menés par des acteurs sérieux et y mobilisant des moyens importants en argent et en compétence. Bonne nouvelle pour les collectivités ! Par contre, on est dans le registre du gros projet structurel davantage que dans la bidouille agile et productrice de ruptures sociales et économiques profitables. On est dans le raisonnable et dans le planifié, pourriez-vous me dire : on ne change pas la société avec de la techno ? Quoique, il faut bien la changer avec quelque chose, non ? Ou bien, à tout le moins, les projets les plus innovants menés par la Caisse des Dépôts (cartables numériques, …) sont encore loin d’avoir fait leurs preuves. Et ces preuves ne semblent attendues qu’à long terme. De la Caisse des Dépôts à la startup, il y a une différence, non ? OK.
Bonne pioche avec la caisse des dépôts. Cette étape de ma recherche a été fructueuse en renseignements et en prises de contact. Voila une équipe centrée sur les innovations Internet d’utilité publique, pas de doute, même si l’approche adoptée semble bien loin du social entrepreneurship d’une part, de la garage company d’autre part. Mais il ne faut pas s’en étonner, on reste dans le domaine du financement de projets du secteur public.
Et l’opérateur historique, alors ? Fabien m’a mis en contact avec Pierre. Pierre, chercheur et entrepreneur dans l’âme, connaît par coeur France Telecom pour y travailler depuis longtemps déjà. Pierre m’accueille chaleureusement au centre de recherche de France Telecom et me met immédiatement au parfum : faut pas rêver, c’est pas chez FT qu’on trouvera de l’innovation Internet d’utilité publique. D’ailleurs, d’après lui, la rumeur est exacte : on n’y trouvera pas d’innovation tout court. FT a un beefsteak à défendre et il se passera encore longtemps avant que FT ne se retrouve en situation tellement concurrentielle qu’il sera forcé à innover pour conquérir de nouveaux marchés. Le trait est sans doute un peu forcé mais à peine. Et, bureaucratie faisant, ce n’est pas un environnement propice à l’innovation. Mais alors, pourquoi ces observations ne s’appliqueraient pas également à la caisse des dépôts ? En appliquant mes observations de la caisse des dépôts, et en étant optimiste, on peut au mieux imaginer qu’il existe chez FT quelques écosystèmes de niche internes au sein desquelles susbsitent des équipes mobilisant des moyens importants pour construire et commercialiser des offres de services nouvelles et répondant à des besoins d’acteurs publics ou de véritables attentes sociales ?
Pierre a en tout cas achevé de me décourager à chercher dans l’immédiat des pistes d’IIUPs chez France Telecom. Au contraire, il me donne généreusement de nombreuses pistes pertinentes à explorer dans son carnet d’adresses.
Une de mes anciennes collègues de travail m’avait fait découvrir l’économie de communion. A l’occasion d’une conférence sur ce thème, je rencontre la directrice d’un groupe agro-alimentaire. Celle-ci cherche maintenant à mettre ses compétences managériales et entreprenariales au service d’enjeux d’utilité publique, sur des thématiques de développement durable. Peu familière de l’univers des nouvelles technologies, elle m’invite cependant à rencontre Bernard un business angel qui cherche à répondre à des problématiques d’utilité publique par les outils du financement et de l’accompagnement de petites entreprises. Celui-ci évoque avec moi quelques projets sur lesquels il travaille. Il se révèle l’une des rares personnes rencontrées qui se situe à l’exact croisement des démarches d’innovation et de réponse à des enjeux d’utilité publique, plus particulièrement environnementales. Il me prouve, si cela était nécessaire, que les acteurs du secteur public sont bien loin d’avoir le monopole des innovations d’utilité publique. Nous évoquons ce en quoi l’Internet pourrait être utile pour de tels projets : du plus utopique avec la commercialisation de services en lignes de médiation appliqués au développement local jusqu’au plus prosaïque avec celle de services en ligne d’information sur la qualité de l’environnement dans les grandes villes françaises. Bernard semble un pont rare entre pur entreprenariat et économie sociale. Il serait sans doute une aide précieuse pour les social entrepreneurs qui émergeront un jour sur les marchés français.
Je ne peux terminer cette expédition estivale sans prendre le temps d’appeler mon pote Jean-Paul. Jean-Paul, ancien directeur d’association est aujoud’hui consultant Internet expérimenté auprès de collectivités locales et du tiers secteur. Il m’explique pourquoi son projet de création d’entreprise d’insertion par les nouvelles technologies n’a jamais pu voir le jour : l’incompétence professionnelle d’institutionnels de l’insertion pour l’économique y est pour quelque chose. Le dégoût et la méfiance des “vieux roudoudous du monde associatif” n’y sont pas pour rien. Alors, tout espoir est-il perdu de voir un jour des innovations privées répondant à des enjeux d’utilité publique à l’aide des technologies Internet ? Jean-Paul pense qu’aujourd’hui, les seuls acteurs qui peuvent prétendre à faire du sérieux dans le domaine, ce sont les équipes d’ingénierie des télécommunications des grosses ONG internationales, quoique ce ne soit certes pas dans une démarche entreprenariale. Alors, où verra-t-on de vraies IIUP demain ? Il hésite un instant et me confie : l’enjeu d’utilité publique auxquelles de telles innovations pourraient répondre de la manière la plus profitable, c’est le financement de micro-projets associatifs. Oh-oh ! Voila qui m’inspire… Il faudra que je (lui et) vous présente bientôt le projet que cette idée m’inspire.
Cette expédition a pris fin dans le courant de l’été : il fallait bien que je parte véritablement en vacances à un moment donné, non ?! Récapitulons les questions que je me posais initialement et mes conclusions à ce stade de mes recherches :
- les innovations Internet d’utilité publique ne sont plus totalement terra incognita puisque je suis revenu vivant de cette expédition pour vous en parler
- Peut-on répondre durablement à des enjeux d’utilité publique avec l’Internet ? Je n’en ai pas acquis la preuve mais nous sommes nombreux à y croire, alors pourquoi pas.
- Les IIUPs, est-ce que ça existe vraiment ? est-ce un OVNI ? Peut-on faire de l’innovation Internet d’utilité publique à grande échelle et avec des moyens vraiment conséquents ? Ces entretiens m’ont permis de rencontrer plusieurs personnes affirmant qu’ils ont vu voire rencontré des IIUPs. Pour certains, il s’agit même de sujets de travail sur lesquels sont mobilisés des moyens significatifs dans quelques grandes organisations.
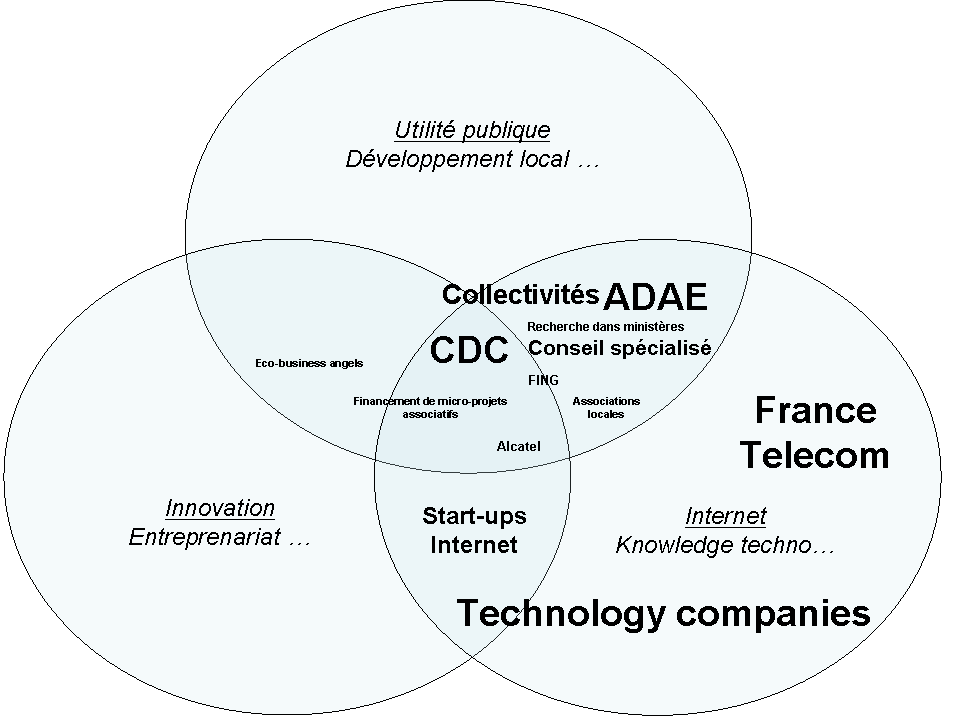
- Qui s’est déjà attelé à de tels projets ? La carte ci-dessous récapitule les principaux acteurs que j’ai pu répérer et/ou rencontrer jusqu’ici. Il me faudra un jour positionner sur cette carte des acteurs tels que le Réseau Idéal, 6nergies, Ilog, Sofrecom, l’UNIT Consortium, Sopinspace, la DATAR, Ashoka, Navidis, Novethic et d’autres…
Malheureusement, l’été a été trop court pour explorer toutes les pistes qui se sont offertes à moi. Et, reprise oblige, j’ai moins de temps pour explorer ces pistes par des entretiens face-à-face (sauf à déjeuner ensemble, bien sûr). Alors je me tourne également vers vous pour m’aider à affiner ces idées. Comment croiser, en France, utilité publique, entreprenariat et nouvelles technologies ? Ces ingrédients peuvent-ils prendre en mayonnaise ? Où sont les grands Chefs cuistot en la matière ? J’aimerais savoir ce que tout cela vous inspire. Comment voyez-vous les choses ? Qui peut me donner plus de tuyaux à ce sujet ? Comment poursuivre cette exploration et dans quelles directions ?
How to ReSTfully Ajax
Here are some pointers for learning more about the Ajax programming model and how to properly design your Ajax application :
- Ajax is said to be the cross-platform successor to Java… huh… (David, thank you for this pointer)
- Ajax should be ReSTfully considered before use
- Is Ajax ReSTless and dirty ?
While I am mentionning the Representational State Transfer (ReST) architecture style, here are some additional and valuable resources on this topic :
- Do we need a ReST toolkit for application developpers ? What would it look like ?
- NetKernel is claimed to be such a ReSTful toolkit
- A ReSTful toolkit for application developers would be a low cost disruption to the heavyweight SOA products that are (by far) overshooting the market of IT departments in big corporations ; it nicely fits the Christensen model of disruptive innovations
Publications, brevets et innovations en tant que chercheur aux Motorola Labs
[Ceci est le résumé de l’une de mes réalisations professionnelles. Je m’en sers pour faire ma pub dans l’espoir de séduire de futurs partenaires. Plus d’infos à ce sujet dans le récit de mon parcours professionnel.]
En 2005, je rejoins les laboratoires de recherche appliquée de Motorola. Je prends la direction de l’équipe française en charge des systèmes de raisonnement et d’apprentissage automatiques pour la personnalisation des contenus et applications mobiles. En deux ans, je co-écris 1 livre technologique cofinancé par l’Union Européenne, 2 brevets et 3 publications académiques. En tant que représentant de Motorola au pôle de compétitivité Cap Digital, je rencontre les dirigeants de plusieurs jeunes entreprises innovantes parisiennes et, sur la base de ces partenariats possibles, je propose à ma hiérarchie 6 projets d’innovations. Je propose une dizaine de projets d’innovation pour notre incubateur interne “Early Stage Accelerator” et j’obtiens le feu vert et un coach pour démarrer l’incubation de 3 de ces projets dans les domaines de la publicité personnelle non invasive, des guides interactifs de programmes TV et de l’édition de contenus personnalisés pour téléphones. Malheureusement, suite aux mauvaises ventes de téléphones en Inde et en Chine, Motorola se restructure et ferme peu après tous ses centres de recherche en Europe.
Innovation industrielle, et Internet dans tout ça ?
Le rapport de Jean-Louis Beffa à Jacques Chirac a donné lieu à la création d’une agence pour l’innovation industrielle doté d’un joli budget. Ce rapport a été discuté dans la blogosphère.
Certains ont été notamment surpris de l’absence d’un axe prioritaire “Technologies de l’Information et de la Communication” dans ce rapport et ont souligné combien d’autres pays avaient au contraire misé sur l’innovation dans les TIC, les STIC (Sciences et …), les NTIC (Nouvelles… ce qui fait déjà un peu ancien).
Histoire d’apporter ma pierre à l’édifice de la critique (constructive), voici deux documents qui soulignent l’importance prioritaire que les TIC devraient avoir dans une politique d’innovation industrielle en France.
Le premier est un rapport d’étude du conseil stratégique des technologies de l’information auprès du premier ministre, portant sur les politiques de R&D sur les STIC dans les grands pays industriels. Il montre que l’Europe est largement en retard par rapport au Japon et aux USA en matière de R&D sur les NTIC.
Le deuxième document est le bulletin de juin 2005 du centre d’analyse statistique du Canada, portant sur l’innovation. Il indique :
Les résultats de l’Enquête sur l’innovation de 2003, qui portait sur l’innovation dans certaines industries de services, montrent que les établissements des industries de services des TIC sont les plus susceptibles d’être innovateurs. Au Canada, les trois industries où les taux d’innovation étaient les plus élevés appartenaient toutes aux TIC.
En l’occurence, il s’agit des éditeurs logiciels, des opérateurs satellite ou Internet et, dans une moindre mesure, des SSII et du conseil, des bureaux d’études, sociétés d’ingénierie ou de R&D et, enfin, des grossistes-distributeurs high-tech. Il me semble donc que l’agence française pour l’innovation industrielle néglige l’innovation dans l’industrie des services en ne prévoyant aucune priorité politique pour les TIC alors que, dans des pays tels que le Canada, les TIC sont perçues comme un secteur prioritaire d’innovation. On dit que les grands capitaines d’industrie, tels que M. Beffa, ne voient parfois dans l’informatique qu’un “mal nécessaire” (à la bonne gestion, notamment financière, des industries “lourdes”). Ceci explique-t-il cela ?
PS : Au passage, dans le document canadien, vous noterez que
les entreprises qui sont situées à proximité d’entreprises rivales ou d’universités ne sont pas plus
innovatrices que les autres de la même industrie, sauf quand la distance est extrêmement courte.
Il est précisé, un peu plus loin :
La proximité avec des entreprises rivales ou des universités semble favoriser l’innovation uniquement lorsque les distances sont très courtes (quelques centaines de mètres). Et même dans ces cas, la proximité n’a des répercussions que sur certains types d’innovations. La proximité étroite avec des entreprises rivales semble favoriser l’imitation plutôt que les innovations originales, tandis que la proximité étroite avec des universités semble favoriser les innovations originales plutôt que les imitations.
Alors, que penser de cet autre volet des politiques françaises de soutien à la R&D, qui passe par le développement de “pôles de compétitivité” censés rapprocher physiquement entreprises rivales et universités ? Le fond a certainement du bon. Mais a-t-on pensé à prescrire une distance limite au-delà desquels le pôle n’a plus de sens ni d’intérêt ?
Semantic Web reports for corporate social responsability
With that amount of buzzwords in the title, I must be ringing some warning bells in your minds. You would be right to get cautious with what I am going to say here because this is pure speculation. I would like to imagine how annual (quarterly ?) corporate reports should look like in some near future.
In my opinion, they should carry on the current trend on emphasizing corporate social responsability. In order to do so, they should both embrace innovative reporting standards and methodologies and support these methodologies by implementing them with “semantic web”-like technologies. In such a future, it would mean that financial analyst (and eventually stakeholders) should be able to browse through specialized web sites which would aggregate meaningful data published in these corporate reports. In such specialized web sites, investors should be able to compare comparable data, marks and ratings regarding their favorite corporations. They should be given functionalities like the one you find in multidimensional analysis tools (business intelligence), even if they are as simplified as in interactive purchase guides [via Fred]. In such a future, I would be able to subscribe to such a web service, give my preferences and filters in financial, social and environmental terms. This service would give me a snapshot of how the selected corporations compare one to each other regarding my preferences and filters. Moreover, I would receive as an RSS feed an alert whenever a new report is published or when some thresholds in performance are reached by the corporations I monitor.
Some technological issues still stand in the way of such future. They are fading away. But a huge amount of methodological and political issues stand there also… What if such technologies come to maturity ? Would they push corporations, rating agencies, analysts and stakeholders to change their minds and go in the right direction ?
Projet Internet de rue: Appel à nos amis roumains !
Y a-t-il des roumains de Roumanie dans la salle ? En France, il y en a dans la rue, qui n’ont pas forcément beaucoup de moyens mais
ont l’audace de goûter aux nouvelles technos. [Je précise après coup qu’il s’agit de roumains gitans car un lecteur roumain s’est senti offensé de l’absence de cette précision, cf. la discussion plus bas.] Ils aimeraient bien communiquer par Internet avec leur famille restée au pays, pour échanger quelques photos du fils que l’on a pas revu depuis deux ans… Problème : au pays, qui pourra donner (prêter ?) à cette famille un accès à l’Internet ? Faites passer cet appel à vos contacts en Roumanie, ça pourrait être sympa. Au passage, découvrez le formidable projet Internet de rue.
Social software for skyscrapers
(Via Designing for Civil Society). iSociety was exploring the idea of using social software in local contexts, specifically in a local residential area (a set of skyscrapers). They see the potential of social software in its ability to
- facilitate better face-to-face [communication] : create introductions between people who recognise their shared interests and want to meet
- circumvent face-to-face [communication] : enable weak norms of cooperation between people who don’t want to meet, or can’t, but still have shared interests (which they may not even be aware of)
I would call this last case “loosely coupled communication” in the same way the blogosphere enables distributed conversation.
They identified three fields of use for local social software :
- infrastructure : transforming your local facility manager into a blogger so that residents get involved in managing shared facilities (elevators, shared areas, …)
- tasks : facilitating the scheduling of activities such as sport, local trade or childcare with an online reputation system and group forming features
- culture: for people interested in linkage with neighbours for it’s own sake
They think the higher potential is in the “task” field because
studies show that activities such as these which require cooperation have a better impact on social capital than projects such as community centres, which promote cooperation.
In other words, as they say :
Social capital is best pursued obliquely
Their conclusion that local residential areas may not need generic social software but task-oriented social software.
This reminds me of a community project I ran when I was younger : the volunteer team I was part of wanted to socialize with some youngsters who lived in nearby slums because we were curious about how it was to live in such poor districts. The best way we found to get into this distant social context was to first identify a very concrete project that would require us to meet these other teenagers. We heard a local association in such a slum was training volunteers in improvised acting. My team was poor on acting but we were strong in video technical skills. So we had in hand a reason to go to this association and ask for help to complete our task/project : making a short video fiction with other young volunteers. We made this short movie together (it took one year of work during our week-ends) and it was a lot of fun ! Moreover, this project was a success in building local social capital because it was task-oriented and its success required strong cooperation.
Using social software locally
Yet another idea of innovation that has been floating around, in the blogosphere and in my wish list : inventing/deploying systems that connect people one with another in local contexts.
The main idea of such systems is that they are
- useful locally : they stimulate the development of connexions between persons on a given place or neighborhood :
- their output = development of new projects, partnership building, local business transactions, meeting new people, involvement and participation in local activities and projects
- they connect people who share :
- a common event (exhibition, meeting, forum, conference, trade show)
- or a common area (district, city, business area, public place or infrastructure)
- tools in the hands of facilitators and mediators, people who act as hubs and networkers, so that these people can generate a wider and more efficient scope of socialization
- technical innovations because they rely on emerging technologies such as social software (including blogging), advanced identity management, semantic technologies, knowledge technologies, …
Potential issues : Privacy of data generates important legal and technical difficulties ; data describing individual is precious and difficult to access and manage with good-enough privacy guarantees ; there is a high risk that these systems won’t be used the way they were intended to ; change management is an issue when working with local organizers/networkers/mediators who tend to discard technical innovations as not-enough-human and/or fear for their jobs ; these technologies are far from mature !
Potential market #1 : social networking during events :
- Sector : professional events marketing and organization, with organizers of trade shows, of conferences, meeting events
- Profile of a sponsor : a company with a very “high-tech” profile on its market, with the will and characteristics of an innovator
- Issues at stake : Event makers say the main value they provide is the social connexions their event provides to their customers ; they want to facilitate the connexion between exhibitors and participants or between participants themselves ; they want to make these connexions persistent after the end of the event ; their purpose may be to enhance the satisfaction of exhibitors and/or participants.
- But… I don’t know this sector so your feedback and ideas are appreciated !
- Example of such a business : Jambo for conferences
Potential market #2 : social network for local development
- Sector : urban planning and local development, with a public agency (national agency for urban renewal, regional council, public institution), or para-public organization (non-profit, “hybrid economy company” delivering services to cities) in charge of the development of a given area
- Issues at stake : In the field of local development, one big target is to develop sustainable social or business relationships in a given area. But local developers only act indirectly on these relationships : urban planning, area marketing, public services, … In the best situations, their mediation and networking efforts hardly rely on human handcraft. The issue at stake is to systematize and extend these networking practices and to exploit the address books of local actors at their best.
- But… social software are “hard” industrial tools applied to a “soft” issue ; they aren’t seen as useful because the tools are here but the profitable uses are not validated. And fortunately, public agencies don’t invest money on “soft” issues handled with industrial tools !
An open source foundation for Fortune 500 companies
Another un-used business idea to recycle… please follow me :
- Fortune 500 companies produce a lot of in-house developments, reinventing the wheel again and again, especially in the field of non-critical, non-business applications : reporting applications, technical asset management, collaborative tools, IT security, identity management, content management… Each of them is sitting on a consequent catalog of custom-made “commodity” applications that they develop and maintain on their own.
- Most of these non-critical-non-business-in-house developments have a limited value but a high cost for businesses.
- The main priority of corporate IT departments is to reduce their costs ; most of them rely on outsourcing applicative developments to some extent.
- Open source is now somewhat trendy even among Fortune 500 corporations ; it is reaching a high level of visibility and acceptability.
- The open source model proposes an optimization of the costs sketched above by sharing them among several users of commodity applications, i.e. by open sourcing them.
- The “open sourcing” of custom-made applications by Fortune 500 companies would be an alternative to the classical outsourcing of these development and maintenance costs.
- The offshore outsourcing of corporate development is seen as a threat on jobs for IT programmers in northern countries ; but the open sourcing of this software could be seen as more acceptable.
- These IT departments are currently converging to common technological frameworks : .Net, J2EE, open source scripting ; that movement enhances their capability to absorb “foreign” developments ; and the standardization of their architectures tends to enhance the re-usability of their in-house developments.
- Open source foundations are legal entities designed to own the intellectual property of open source applications, to guarantee that the open source licence they are distributed under will be enforced, to promote these applications so that their communities are thriving and the applications make gains in terms of reliability, quality and sustainability.
- The distribution of software under open source licences is said to represent the highest value transfer ever from rich countries to developping countries.
- The open sourcing of these Fortune 500 applications would be a positive change both for big corporations themselves and for smaller companies especially in third world countries.
- Social entrepreneurship is becoming a hot topic today even in mainstream media ; this initiative might qualify as a social entrepreneurship initiative ; the public usefulness of such a move might justify the legal creation of a foundation in France.
- Recently, in France, foundations have gained in acceptance by big businesses since a new tax law offers higher opportunities for tax reductions.
- I still work as an IT manager in the global IT department for a Fortune 100 company in France ; our CIO would see such an open source foundation as a positive initiative but, as a cautious manager, he is dubious regarding the willingness of other CIOs of Fortune 500 companies (in France) to share their custom codes under an open source licence.
You work in/for a big corporation willing to reality-check this idea ? What do you think ?
Recycling un-used business ideas
As a former entrepreneur and a compulsive innovator, too many ideas of new businesses tend to leak out of my mind. Most of them are very so-so and I will not implement them. But it would be stupid not to recycle them in my process of open-sourcing my quest for networked intelligence. In simpler words : let’s share with you some more or less stupid business ideas. They will come into my usual wishlist. Your comments will be very much appreciated. Let’s start with an idea on … recycling laptops into digital frames.
If you read Slashdot, you will be familiar with this kind of digital frame. The idea is that many do-it-yourself guys can turn old laptops into digital frames displaying holiday pictures as slideshows in the living room. Let’s consider the facts :
{kind=link}
- laptops are expensive to recycle and a dangerous waste for the environment ; users companies and retailers (or cities) pay for getting rid of them
- DIY guys can turn them into digital frames
- I’d like to have such a digital frame equipped with a wifi connexion in order to display the pictures freshly taken from my digital camera
- the digital frame might be the ideal companion for digital cameras (more than printers ?)
- this business idea has already been implemented but I imagine this is a quite a small niche market.
- In France, the Envie company “recycles” jobless people into experts in recycling electronic equipment.
Why not implement this business in Europe with a lower cost solution : either offshore or locally within the social economy sector ?
Web scraping with Python (part II)
The first part of this article dealt with retrieving HTML pages from the web with the help of a mechanize-propelled web crawler. Now your HTML pieces are safely saved locally on your hard drive and you want to extract structured data from them. This is part 2, HTML parsing with Python. For this task, I adopted a slightly more imaginative approach than for my crawling hacks. I designed a data extraction technology based on HTML templates. Maybe this could be called “reverse-templating” (or something like template-based reverse-web-engineering).
You may be used with HTML templates for producing HTML pages. An HTML template plus structured data can be transformed into a set of HTML pages with the help of a proper templating engine. One famous technology for HTML templating is called Zope Page Templates (because this kind of templates is used within the Zope application server). ZPTs use a special set of additional HTML tags and attributes referred to by the “tal:” namespace. One advantage of ZPT (over competing technologies) is that ZPT are nicely rendered in WYSIWYG HTML editors. Thus web designers produce HTML mockups of the screens to be generated by the application. Web developpers insert tal: attributes into these HTML mockups so that the templating engine will know which parts of the HTML template have to be replaced by which pieces of data (usually pumped from a database). As an example, web designers will say <title>Camcorder XYZ</title> then web developpers will modify this into <title tal:content=”camcorder_name”>Camcorder XYZ</title> and the templating engine will further produce a <title>Camcorder Canon MV6iMC</title> when it processes the “MV6iMC” record in your database (it replaces the content of the title element with the value of the camcorder_name variable as it is retrieved from the current database record). This technology is used to merge structured data with HTML templates in order to produce Web pages.
I took inspiration from this technology to design parsing templates. The idea here is to reverse the use of HTML templates. In the parsing context, HTML templates are still produced by web developpers but the templating engine is replaced by a parsing engine (known as web_parser.py, see below for the code of this engine). This engine takes HTML pages (the ones you previously crawled and retrieved) plus ZPT-like HTML templates as input. It then outputs structured data. First your crawler saved <title>Camcorder Canon MV6iMC</title>. Then you wrote <title tal:content=”camcorder_name”>Camcorder XYZ</title> into a template file. Eventually the engine will output camcorder_name = “Camcorder Canon MV6iMC”.
In order to trigger the engine, you just have to write a small launch script that defines several setup variables such as :
- the URL of your template file,
- the list of URLs of the HTML files to be parsed,
- whether you would like or not to pre-process these files with an HTML tidying library (this is useful when the engine complains about badly formed HTML),
- an arbitrary keyword defining the domain of your parsing operation (may be the name of the web site your HTML files come from),
- the charset these HTML files are made with (no automatic detection at the moment, sorry…)
- the output format (csv-like file or semantic web document)
- an optional separator character or string if ever you chose the csv-like output format
The easiest way to go is to copy and modify my example launch script (parser_dvspot.py) included in the ZIP distribution of this web_parser.
Let’s summarize the main steps to go through :
- install utidylib into your python installation
- copy and save my modified version of BeautifulSoup into your python libraries directory (usually …/Lib/site-packages)
- copy and save my engine (web_parser.py) into your local directory or into you python libraries directory
- choose a set of HTML files on your hard drive or directly on a web site,
- save one of these files as your template,
- edit this template file and insert the required pseudotal attributes (see below for pseudotal instructions, and see the example dvspot template template_dvspot.zpt),
- copy and edit my example launch script so that you define the proper setup variables in it (the example parser_dvspot.py contains more detailed instructions than above), save it as my_script.py
- launch your script with a python my_script.py > output_file.cowl (or python my_script.py > output_file.cowl)
- enjoy yourself and your fresh output_file.owl or output_file.csv (import it within Excel)
- give me some feedback about your reverse-templating experience (preferably as a comment on this blog)
This is just my first attempt at building such an engine and I don’t want to make confusion between real (and mature) tal attributes and my pseudo-tal instructions. So I adopted pseudotal as my main namespace. In some future, when the specification of these reverse-templating instructions are somewhat more stabilized (and if ever the “tal” guys agree), I might adopt tal as the namespace. Please also note that the engine is somewhat badly written : the code and internal is rather clumsy. There is much room for future improvement and refactoring.
The current version of this reverse-templating engine now supports the following template attributes/instructions (see source code for further updates and documentation) :
- pseudotal:content gives the name of the variable that will contain the content of the current HTML element
- pseudotal:replace gives the name of the variable that will contain the entire current HTML element
- (NOT SUPPORTED YET) pseudotal:attrs gives the name of the variable that will contain the (specified?) attribute(s ?) of the current HTML element
- pseudotal:condition is a list of arguments ; gives the condition(s) that has(ve) to be verified so that the parser is sure that current HTML element is the one looked after. This condition is constructed as a list after BeautifulSoup fetch arguments : a python dictionary giving detailed conditions on the HTML attributes of the current HTML element, some content to be found in the current HTML element, the scope of research for the current HTML element (recursive search or not)
- pseudotal:from_anchor gives the name of the pseudotal:anchor that is used in order to build the relative path that leads to the current HTML element ; when no from_anchor is specified, the path used to position the current HTML element is calculted from the root of the HTML file
- pseudotal:anchor specifies a name for the current HTML element ; this element can be used by a pseudotal:from_anchor tag as the starting point for building the path to the element specified by pseudotal:from_anchor ; usually used in conjunction with a pseudotal:condition ; the default anchor is the root of the HTML file.
- pseudotal:option describes some optional behavior of the HTML parser ; is a list of constants ; contains NOTMANDATORY if the parser should not raise an error when the current element is not found (it does as default) ; contains FULL_CONTENT when data looked after is the whole content of the current HTML element (default is the last part of the content of the current HTML element, i.e. either the last HTML tags or the last string included in the current element)
- pseudotal:is_id_part a special ‘id’ variable is automatically built for every parsed resource ; this id variable is made of several parts that are concatenated ; this pseudotal:is_id_part gives the index the current variable will be used at for building the id of the current resource ; usually used in conjunction with pseudotal:content, pseudotal:replace or pseudotal:attrs
- (NOT SUPPORTED YET) pseudotal:repeat specifies the scope of the HTML tree that describes ONE resource (useful when several resources are described in one given HTML file such as in a list of items) ; the value of this tag gives the name of a class that will instantiate the parsed resource scope plus the name of a list containing all the parsed resource
The current version of the engine can output structured data either as a CSV-like output (tab-delimited for example) or as an RDF/OWL document (of Semantic-Web fame). Both formats can easily be imported and further processed with Excel. The RDF/OWL format gives you the ability to process it with all the powerful tools that are emerging along the Semantic Web effort. If you feel adventurous, you may thus import your RDF/OWL file into Stanford’s Protege semantic modeling tool (or into Eclipse with its SWEDE plugin) and further process your data with the help of a SWRL rules-based inference engine. The future Semantic Web Rules Language will help at further processing this output so that you can powerfully compare RDF data coming from distinct sources (web sites). In order to be more productive in terms of fancy buzz-words, let’s say that this reverse-templating technology is some sort of a web semantizer. It produces semantically-rich data out of flat web pages.
The current version of the engine makes an extensive use of BeautifulSoup. Maybe it should have been based on a more XMLish approach instead (using XML pathes ?). But it would have implied that the HTML templates and HTML files to be processed should then have been turned into XHTML. The problem is that I would then have relied on utidylib but this library breaks too much some mal-formed HTML pages so that they are not valuable anymore.
Current known limitation : there is currently no way to properly handle some situations where you need to make the difference between two similar anchors. In some cases, two HTML elements that you want to use as distinct anchors have in fact exactly the same attributes and content. This is not a problem as long as these two anchors are always positioned at the same place in all the HTML page that you will parse. But, as soon as one of the anchors is not mandatory or it is located after a non mandatory element, the engine can get lost and either confuse the two anchors or complain that one is missing. At the moment, I don’t know how to handle this kind of situation. Example : long lists of specifications with similar names where some specifications are optional (see canon camcorders as an example : difference between lcd number of pixels and viewfinder number of pixels). The worst case scenario would be when there is a flat list of HTML paragraphs. The engine will try to identify these risks and should output some warnings in this kind of situations.
Here are the contents of the ZIP distribution of this project (distributed under the General Public License) :
- web_parser.py : this is the web parser engine.
- parser_dvspot.py : this is an example launch script to be used if you want to parser HTML files coming from the dvspot.com web site.
- template_dvspot.zpt : this is the example template file corresponding to the excellent dvspot.com site
- BeautifulSoup.py : this is MY version of BeautifulSoup. Indeed, I had to modify Leonard Richardson’s official one and I couldn’t obtain any answer from him at the moment regarding my suggested modifications. I hope he will soon answer me and maybe include my modifications in the official version or help me overcoming my temptation to fork. My modifications are based on the official 1.2 release of beautifulsoup : I added “center” as a nestable tag and added the ability to match the content of an element with the help of wildcards. You should save this BeautifulSoup.py file into the “Lib\site-packages” folder of your python installation.
- README.html is the file you are currently reading, also published on my blog.
P2P + Web Sémantique + Réseaux sociaux + Bureautique = ?
Prenez une once de peer-to-peer, trois coudées de web sémantique, deux livres de bureautique et un denier de réseau sociaux, malaxez avec énergie et vous obtenez… le “Networked Semantic Desktop”. Ca c’est de la convergence où je ne m’y connais pas… Projet de recherche, circulez, il n’y a rien à télécharger ! Vu également ici.
Web scraping with python (part 1 : crawling)
Example One : I am looking for my next job. So I subscribe to many job sites in order to receive notifications by email of new job ads (example = Monster…). But I’d rather check these in my RSS aggregator instead of my mailbox. Or in some sort of aggregating Web platform. Thus, I would be able to do many filtering/sorting/ranking/comparison operations in order to navigate through these numerous job ads.
Example Two : I want to buy a digital camcorder. So I want to compare the available models. Such a comparison implies that I rank the most common models according to their characteristics. Unfortunately, the many sites providing reviews or comparisons of camcorders are not often comprehensive and they don’t offer me the capability of comparing them with respect to my way of ranking and weighting the camcorder features (example = dvspot). So I would prefer pumping all the technical stuff from these sites and manipulate this data locally on my computer. Unfortunately, this data is merged within HTML. And it may be complex to extract it automatically from all the presentation code.
These are common situations : interesting data spread all over the web and merged in HTML presentation code. How to consolidate this data so that you can analyze and process it with your own tools ? In some near future, I expect this data will be published so that it is directly processable by computers (this is what the Semantic Web is intending to do). For now, I was used to do it with Excel (importing Web data, then cleaning it and the like) and I must admit that Excel is fairly good at it. But I’d like some more automation for this process. I’d like some more scripting for this operation so that I don’t end with inventing complex Excel macros or formulas just to automate Web site crawling, HTML extraction and data cleaning. With such an itch to scratch, I tried to address this problem with python.
This series of messages introduces my current hacks that automate web sites crawling and data extraction from HTML pages. The current output of these scripts is a bunch of CSV files that can be further processed … in Excel. I wish I would output RDF instead of CSV. So there remains much room for further improvement (see RDF Web Scraper for a similar but approach). Anyway… Here is part One : how to crawl complex web sites with Python ?. The next part will deal with data extraction from the retrieved web pages, involving much HTML cleansing and parsing.
My crawlers are fully based on the John L. Lee’s mechanize framework for python. There are other tools available in Python. And several other approaches are available when you want to deal with automating the crawling of web sites. Note that you can also try to scrape the screens of legacy terminal-based applications with the help of python (this is called “screen scraping”). Some approaches of web crawling automation rely on recording the behaviour of a user equipped with a web browser and then reproduce this same behaviour in an automated session. That is an attractive and futuristic approach. But this implies that you find a way to guess what the intended automatic crawling behaviour will be from a simple example. In other words, with this approach, you have either to ask the user to click on every web link (all the job postings…) and this gives no value to the automation of the task. Or your system “guesses” what automatic behaviour is expected just by recording a sample of what a human agent would do. Too complex… So I preferred a more down-to-earth solution implying that you write simple crawling scripts “by hand”. (You may still be interested in automatically record user sessions in order to be more productive when producing your crawling scripts.) As a summary : my approach is fully based on mechanize so you may consider the following code as example of uses of mechanize in “real-world” situations.
For purpose of clarity, let’s first focus on the code part that is specific to your crawling session (to the site you want to crawl) . Let’s take the example of the dvspot.com site which you may try to crawl in order to download detailed description of camcorders :
# Go to home page
#
b.open("http://www.dvspot.com/reviews/cameraList.php?listall=1&start=0")
#
# Navigate through the paginated list of cameras
#
next_page = 0
while next_page == 0:
#
# Display and save details of every listed item
#
url = b.response.url
next_element = 0
while next_element >= 0:
try:
b.follow_link(url_regex=re.compile(r"cameraDetail"), nr=next_element)
next_element = next_element + 1
print save_response(b,"dvspot_camera_"+str(next_element))
# go back to home page
b.open(url)
# if you crawled too many items, stop crawling
if next_element*next_page > MAX_NR_OF_ITEMS_PER_SESSION:
next_element = -1
next_page = -1
except LinkNotFoundError:
# You certainly reached the last item in this page
next_element = -1
#
try:
b.open(url)
b.follow_link(text_regex=re.compile(r"Next Page"), nr=0)
print "processing Next Page"
except LinkNotFoundError:
# You reached the last page of the listing of items
next_page = -1
You noticed that the structure of this code (conditional loops) depends on the organization of the site you are crawling (paginated results, …). You also have to specify the rule that will trigger “clicks” from your crawler. In the above example, your script first follows every link containing “cameraDetail” in its URL (url_regex). Then it follows every link containing “Next Page” in the hyperlink text (text_regex).
This kind of script is usually easy to design and write but it can become complex when the web site is improperly designed. There are two sources of difficulties. The first one is bad HTML. Bad HTML may crash the mechanize framework. This is the reason why you often have to pre-process the HTML either with the help of a HTML tidying library or with simple but string substitutions when your tidy library breaks the HTML too much (this may be the case when the web designer improperly decided to used nested HTML forms). Designing the proper HTML pre-processor for the Web site you want to crawl can be tricky since you may have to dive into the faulty HTML and the mechanize error tracebacks in order to identify the HTML mistakes and workaround them. I hope that future versions of mechanize would implement more robust HTML parsing capabilities. The ideal solution would be to integrate the Mozilla HTML parsing component but I guess this will be some hard work to do. Let’s cross our fingers.
Here are useful examples of pre-processors (as introduced by some other mechanize users and developpers) :
class TidyProcessor(BaseProcessor):
def http_response(self, request, response):
options = dict(output_xhtml=1,
add_xml_decl=1,
indent=1,
output_encoding='utf8',
input_encoding='latin1',
force_output=1
)
r = tidy.parseString(response.read(), **options)
return FakeResponse(response, str(r))
https_response = http_response
#
class MyProcessor(BaseProcessor):
def http_response(self, request, response):
r = response.read()
r = r.replace('"image""','"image"')
r = r.replace('"','"')
return FakeResponse(response, r)
https_response = http_response
#
# Open a browser and optionally choose a customized HTML pre-processor
b = Browser()
b.add_handler(MyProcessor())
The second source of difficulties comes from non-RESTful sites. As an example the APEC site (a French Monster-like job site) is based on a proprietary web framework that implies that you cannot rely on links URLs to automate your browsing session. It took me some time to understand that, once loggin in, every time you click on a link, you are presented with a new frameset referring to the URLs that contain the interesting data you are looking for. And these URLs seem to be dependent on your session. No permalink, if you prefer. This makes the crawling process even more tricky. In order to deal with this source of difficulty when you write your crawling script, you have to open both your favorite text editor (to write the script) and your favorite web browser (Firefox of course !). One key knowledge is to know mechanize “find_link” capabilities. These capabilities are documented in _mechanize.py source code, in the find_link method doc strings. They are the arguments you will provide to b.follow_link in order to automate your crawler “clicks”. For more convenience, let me reproduce them here :
- text: link text between link tags: <a href=”blah”>this bit</a> (as
returned by pullparser.get_compressed_text(), ie. without tags but
with opening tags “textified” as per the pullparser docs) must compare
equal to this argument, if supplied - text_regex: link text between tag (as defined above) must match the
regular expression object passed as this argument, if supplied
name, name_regex: as for text and text_regex, but matched against the
name HTML attribute of the link tag - url, url_regex: as for text and text_regex, but matched against the
URL of the link tag (note this matches against Link.url, which is a
relative or absolute URL according to how it was written in the HTML) - tag: element name of opening tag, eg. “a”
predicate: a function taking a Link object as its single argument,
returning a boolean result, indicating whether the links - nr: matches the nth link that matches all other criteria (default 0)
Links include anchors (a), image maps (area), and frames (frame,iframe).
Enough with explanations. Now comes the full code in order to automatically download camcorders descriptions from dvspot.com. I distribute this code here under the GPL (legally speaking, I don’t own the copyleft of this entire code since it is based on several snippets I gathered from the web and wwwsearch mailing list). Anyway, please copy-paste-taste !
from mechanize import Browser,LinkNotFoundError
from ClientCookie import BaseProcessor
from StringIO import StringIO
# import tidy
#
import sys
import re
from time import gmtime, strftime
#
# The following two line is specific to the site you want to crawl
# it provides some capabilities to your crawler for it to be able
# to understand the meaning of the data it is crawling ;
# as an example for knowing the age of the crawled resource
#
from datetime import date
# from my_parser import parsed_resource
#
"""
Let's declare some customized pre-processors.
These are useful when the HTML you are crawling through is not clean enough for mechanize.
When you crawl through bad HTML, mechanize often raises errors.
So either you tidy it with a strict tidy module (see TidyProcessor)
or you tidy some errors you identified "by hand" (see MyProcessor).
Note that because the tidy module is quite strict on HTML, it may change the whole
structure of the page you are dealing with. As an example, in bad HTML, you may encounter
nested forms or forms nested in tables or tables nested in forms. Tidying them may produce
unintended results such as closing the form too early or making it empty. This is the reason
you may have to use MyProcessor instead of TidyProcessor.
"""
#
class FakeResponse:
def __init__(self, resp, nudata):
self._resp = resp
self._sio = StringIO(nudata)
#
def __getattr__(self, name):
try:
return getattr(self._sio, name)
except AttributeError:
return getattr(self._resp, name)
#
class TidyProcessor(BaseProcessor):
def http_response(self, request, response):
options = dict(output_xhtml=1,
add_xml_decl=1,
indent=1,
output_encoding='utf8',
input_encoding='latin1',
force_output=1
)
r = tidy.parseString(response.read(), **options)
return FakeResponse(response, str(r))
https_response = http_response
#
class MyProcessor(BaseProcessor):
def http_response(self, request, response):
r = response.read()
r = r.replace('"image""','"image"')
r = r.replace('"','"')
return FakeResponse(response, r)
https_response = http_response
#
# Open a browser and optionally choose a customized HTML pre-processor
b = Browser()
b.add_handler(MyProcessor())
#
""""
Let's declare some utility methods that will enhance mechanize browsing capabilities
"""
#
def find(b,searchst):
b.response.seek(0)
lr = b.response.read()
return re.search(searchst, lr, re.I)
#
def save_response(b,kw='file'):
"""Saves last response to timestamped file"""
name = strftime("%Y%m%d%H%M%S_",gmtime())
name = name + kw + '.html'
f = open('./'+name,'w')
b.response.seek(0)
f.write(b.response.read())
f.close
return "Response saved as %s" % name
#
"""
Hereafter is the only (and somewhat big) script that is specific to the site you want to crawl.
"""
#
def dvspot_crawl():
"""
Here starts the browsing session.
For every move, I could have put as a comment an equivalent PBP command line.
PBP is a nice scripting layer on top of mechanize.
But it does not allow looping or conditional browsing.
So I preferred scripting directly with mechanize instead of using PBP
and then adding an additional layer of scripting on top of it.
"""
#
MAX_NR_OF_ITEMS_PER_SESSION = 500
#
# Go to home page
#
b.open("http://www.dvspot.com/reviews/cameraList.php?listall=1&start=0")
#
# Navigate through the paginated list of cameras
#
next_page = 0
while next_page == 0:
#
# Display and save details of every listed item
#
url = b.response.url
next_element = 0
while next_element >= 0:
try:
b.follow_link(url_regex=re.compile(r"cameraDetail"), nr=next_element)
next_element = next_element + 1
print save_response(b,"dvspot_camera_"+str(next_element))
b.open(url)
# if you crawled too many items, stop crawling
if next_element*next_page > MAX_NR_OF_ITEMS_PER_SESSION:
next_element = -1
next_page = -1
except LinkNotFoundError:
# You reached the last item in this page
next_element = -1
#
try:
b.open(url)
b.follow_link(text_regex=re.compile(r"Next Page"), nr=0)
print "processing Next Page"
except LinkNotFoundError:
# You reached the last page of the listing of items
next_page = -1
#
return
#
#
#
if __name__ == '__main__':
#
""" Note that you may need to specify your proxy first.
On windows, you do :
set HTTP_PROXY=http://proxyname.bigcorp.com:8080
"""
#
dvspot_crawl()
In order to run this code, you will have to install mechanize 0.0.8a, pullparser 0.0.5b, clientcookie 0.4.19, clientform 0.0.16 and utidylib. I used Python 2.3.3. Latest clientcookie’s version was to be integrated into Python 2.4 I think. In order to install mechanize, pullparser, clientcookie and clientform, you just have to do the usual way :
python setup.py build python setup.py install python setup.py test
Last but not least : you should be aware that you may be breaking some terms of service from the website you are trying to crawl. Thanks to dvspot for providing such valuable camcorders data to us !
Next part will deal with processing the downloaded HTML pages and extract useful data from them.
Rapid manufacturing : the dream factory
Histoire de nous faire rêver un peu, Bruce Sterling décrit dans cet article de Wired comment, d’ici quelques années, les machines de prototypage rapide (imprimantes 3D, découpe laser, frittage laser…) deviendront des outils de fabrication express (rapid manufacturing) puis des outils de fabrication de bureau (desktop manufacturing) pour permettre à vous et moi de faire un “sélectionner Freebox / bouton droit / Imprimer…” pour voir une freebox toute neuve et opérationnelle sortir de votre imprimante de bureau. Rêvons un peu…
En attendant, des sociétés (Zcorp, Stratasys, et dans une moindre mesure le français Phenix systems…) vendent déjà des machines de fabrication express, de la taille d’un gros photocopieur, consommant des matériaux à coût raisonnable (moins de 100 dollar par objet) et fabriquant un objet en quelques heures seulement.
Et une école du Ghana s’équipe avec un “fab lab” du MIT.
3 bouquins pour Noël
Voici trois bouquins que j’ajoute à ma liste du père Noël :
Web scraping with Python
Here is a set of resources for scraping the web with the help of Python. The best solution seems to be Mechanize plus Beautiful Soup.
See also :
- ClientTable (see also this comment)
- DOMForm
- Pull parser
- wwwsearch ‘s FAQ
- Simon Willison’s weblog on this topic
- Dive Into Python’s tutorial on HTML processing
Off-topic : proxomitron looks like a nice (python-friendly ?) filtering proxy.
Visualizing social networks
Social networks are (were ?) trendy these days. What’s missing with social networks is a nice interface so that you can easily browse through one’s social network. This is what this MIT research project was exploring and trying to implement (thank Gouri for the link).
Here are some output my own experiments and implementations on this topic.